A while back I was interviewing for a security role at a rather large company annd a big focus was finding bugs across different projects. Without going into a ton of detail, it’s safe to say that I didn’t exactly land that job at the time. Coming from a pentest/red-teaming track into a more general security engineer or application security engineer means there are a lot of nuances you can miss when it comes to bug hunting.
Recently, however, my work has my finding patterns in codebases that could lead to real issues. As a former mentor once told me, “treat classes of bugs, not singular issues“, things started to click. I tried looking online, but couldn’t find resources I was looking for when it came to this methodology of bug hunting so I wanted to break it down a bit more using the OWASP Juice Shop as our application and codebase. Not just for my own reference, but other security engineers, pentesters, or bug bounty hunters who are facing a similar challenge in their day-to-day work as an in-house pentester or security engineer.
Overview
When searching for bug classes, the idea is that you want to identify dangerous patterns that are similar. So what this means is practice is identiying:
- Known unsafe functions (such as
eval, orexec) - Taking an existing vulnerability’s root cause and deriving a “pattern” that makes it vulnerable
As you can image there are different ways to accomplish the same thing, but I think the following sectuibs will walk you through an example to get familiar with the core concept.
Initial Bug Discovery (XSS)
Since I know Juice Shop is riddled with different kinds of Cross-Site Scripting attacks, I figured this would be a great way to get started. To keep things easy, I decided to just use Docker and run the container locally:
docker run --rm -p 3000:3000 bkimminich/juice-shop
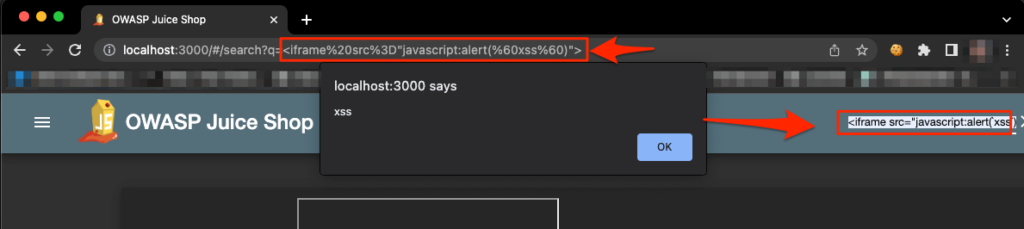
Using the search bar, we can pretty easily find our first XSS using the payload:
<iframe src="javascript:alert(`xss`)">
...
or use the url
...
http://localhost:3000/#/search?q=%3Ciframe%20src%3D%22javascript:alert(%60xss%60)%22%3E
Now since we’re an internal employee of the Juice Shop we not only take this finding seriously, but we leap to the code base to try and figure out how we allow this to happen. Since the search request takes a query parameter q, it’s easy to start from here and work backward to find more instances of this bug once we clone the repo from GitHub.
git clone https://github.com/juice-shop/juice-shop
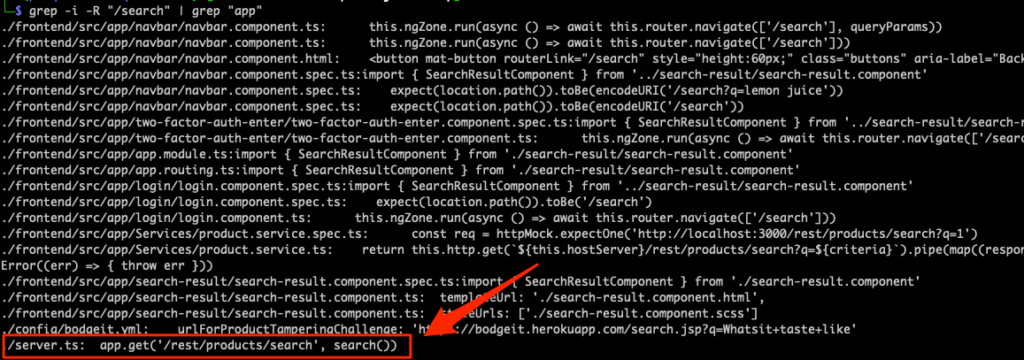
Now we know the route uses a /search endpoint so we can start with that by using grep. We do get a lot of results from integration tests and frontend pages, so we can refine our search results pretty easily by piping one grep into another:
grep -i -R "/search" | grep "app"
Just like that, we’ve identified the route used (/rest/products/search) and where in the codebase it’s located.
We can also search for where the route is specifically used on the frontend to see how it behaves. This is important because, in this case, the frontend renders the XSS payload – not whatever the backend is doing, but we’ll come back to that.
grep -R "/rest/products/search" | grep -v "test"
So let’s recap what we have so far:
- We’ve identified a XSS vulnerability within the search parameter
- Found the route that uses search parameter it and the code
- Identified the frontend component responsible for handling the request + response
Let’s move on.
Identifying the dangerous pattern(s)
Thinking back to XSS basics, we have a source and a sink. This means that there’s a “source” of data entry and a literal “sink” where the data falls and is executed. We have our “source” via the input and API route, but we need to evaluate the sink and see what kind of code pattern it uses.
For the sake of brefity, here’s how I found the sink:
- Open up
./frontend/src/app/Services/product.service.ts - Notice the
ProductServiceclass handles calling the backend REST API - Grep again for the
ProductServiceclass usinggrep -R "ProductService" | grep -v "test" - Locate
./frontend/src/app/search-result/search-result.component.tswhereProductServiceis used - Search for keywords like
queryandsearchto identify the logic that handles the query parameter - Identify line
154that includes an interesting methodbypassSecurityTrustHtml()
What’s now interesting is that the bypassSecurityTrustHtml method is specificly referenced in Angular’s documentation.
Calling any of the
https://angular.io/api/platform-browser/DomSanitizerbypassSecurityTrust...APIs disables Angular’s built-in sanitization for the value passed in.
It’s pretty safe to say we’ve found a dangerous sink.
Identifying bug classes using grep
Now that we know bypassSecurityTrustHtml is in use, it’s pretty easy to find more occurrences. Since the Angular documentation also mentions other bypassSecurityTrust* methods, we can find those in a sweeping search.
grep -R "bypassSecurityTrust" | grep -v ".json"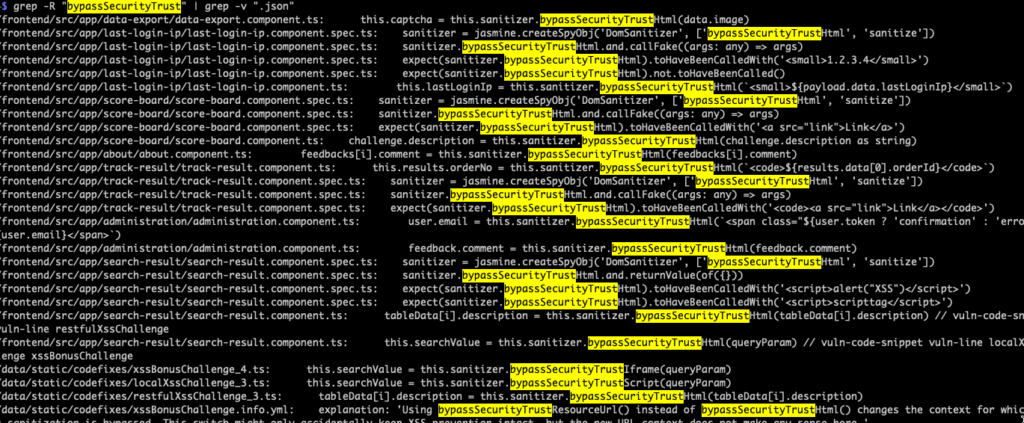
Enhancing discovery with Semgrep
Grep is great and everything, but Semgrep builds upon grep and is much more extensible since it allows you to write your own rules. After you’ve installed Semgrep, you can run it with its auto detection and Semgrep will choose appropriate rules from its registry. For webapps, I love using their OWASP Top 10 rule sets or Javascript/Typescript to kick things off.
semgrep frontend/ --config p/typescript --config p/javascript
The findings we get back are good, some insecure document methods and hard-coded tokens, but they aren’t specific enough for what we want to look for. We can hunt for Angular-specific rules, but it might make more sense to learn how to write our own Semgrep rules.
Implementing a custom Semgrep rule
This won’t cover all of the ins and outs of Semgrep rule writing – there are an incredible amount of configuraitons and options so I’m going to simplify writing a rule to detect our bypassSecurityTrust methods.
As a primer, here’s a little about Semgrep’s rule system:
- Rule are written in YAML format
- Rules can consist of patterns, regexes, or patterns with regexes
- You can write conditionals into the rules to rule out false posiitives
- ex: If a code contains some kind of
safe()function beforeunsafe()is called, the finding will not trigger
- ex: If a code contains some kind of
Let’s first start with the skeleton of the rule we want to create since we know the pattern:
rules:
- id: angular-use-of-bypassSecurityTrust-method
languages:
- javascript
- typescript
message: |
A method that bypasses security trust is used.
severity: ERROR
Now, let’s add a pattern we want to detect using a modified example of Semgrep’s Method Call documentation.
pattern: $O. ... .bypassSecurityTrustHtml(...)When we run Semgrep again with our new rule and our search-result.component.ts file from earlier, we get the following:
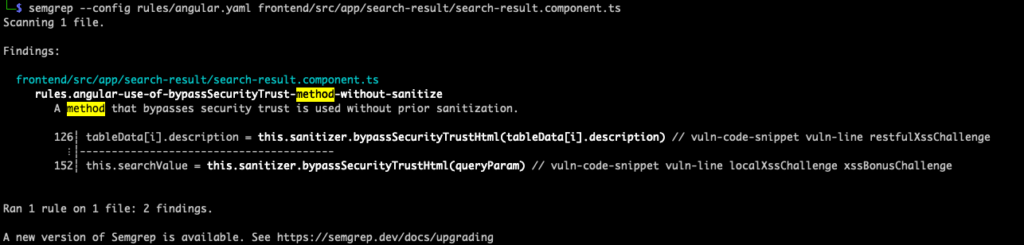
Not a bad start and we did get two findings! The $0 variable followed by the elipses ... tells semgrep to look for some kind of method chaining that ends in bypassSecurityTrustHtml(). But, as we can note in Angular’s documentation, there are multiple methods that use bypassSecurityTrust* and we should focus on classes instead of single bugs. With that in mind, let’s tweak the pattern and use a metadata variable and modify the message.
rules:
- id: angular-use-of-bypassSecurityTrust-method
languages:
- javascript
- typescript
message: |
Method $METHOD is unsafe as it bypasses
Angular's sanitization and should not be used.
severity: ERROR
patterns:
- pattern: $O. ... .$METHOD(...)
- metavariable-regex:
metavariable: $METHOD
regex: bypassSecurityTrust*
The only difference here is we’re telling Semgrep to assign chained methods to a variable called METHOD and then sending it through a very simple regex of bypassSecurityTrust which should blanket capture anytme someone uses that kind of unsafe chained method. With that in mind, let this simple rule against the frontend to see what we get.
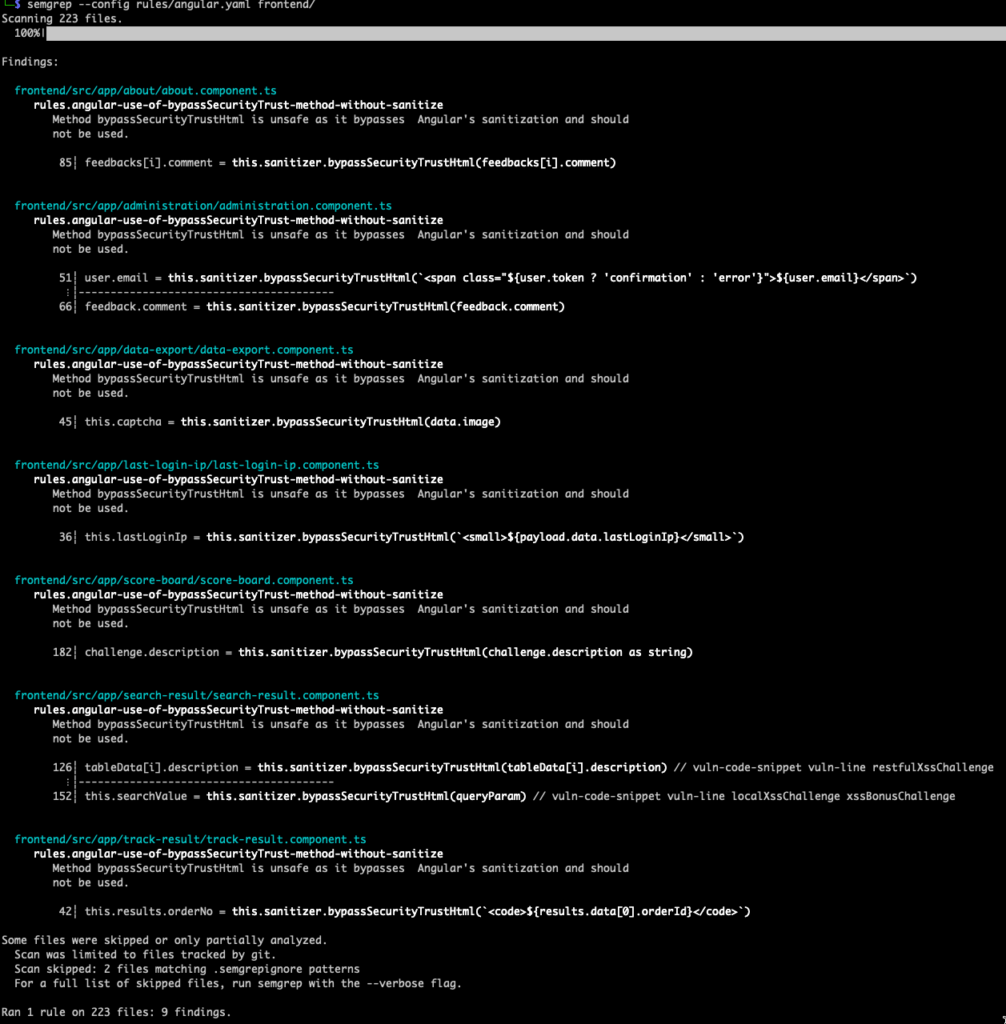
Wow – 7 additional areas where this method was used with just a few lines of code.
Going further and wrapping up
If you noticed, the pattern only detects whenever bypassSecurityTrust* is used in a chained method. This means if someone is calling bypassSecurityTrustHtml specifically, your Semgrep rule might not catch it so there’s room for improvement. Here are some ideas:
- Writing a rule to catch
bypassSecurityTrust*as a function or being reassigned to another variable bypassSecurityTrustbypassSecurityTrustbeing used, but withsanitize()called prior to eliminate false positives- Add “fixes” and resources into your Semgrep rule to help developers understand potential solutions.
Also, if you’re interested, check out R2’s case studies and documentation on writing patterns to catch classes of issues. The tool set is fantastic when tyring to eliminate issue classes instead of specific bugs.